
Read before:
- Which supplier master data is critical?
- How to measure vendor master data quality
- Is there a real problem with my supplier master data?
Do I really need to plan and manage data cleansing?
Suppose that you currently have 12,000 unique active records (unique vendor numbers) in your vendor file where Datanovel check-up finds 7,000 unique legal entities, 45 per cent of which require data cleansing (3,150 unique suppliers). Based on the example in tables 2 and 3, over 1,000 hours will be needed from the team of 7.3 FTE for 4 weeks, being a significant resource and effort that require proper planning and coordination.
Datanovel helps you to plan and manage data cleansing. Please enquire for:
In this article, our approach is described.
Planning data cleansing
Among the three methods of assessing data quality, verification with the issuer (Table 1) requires the greatest effort.
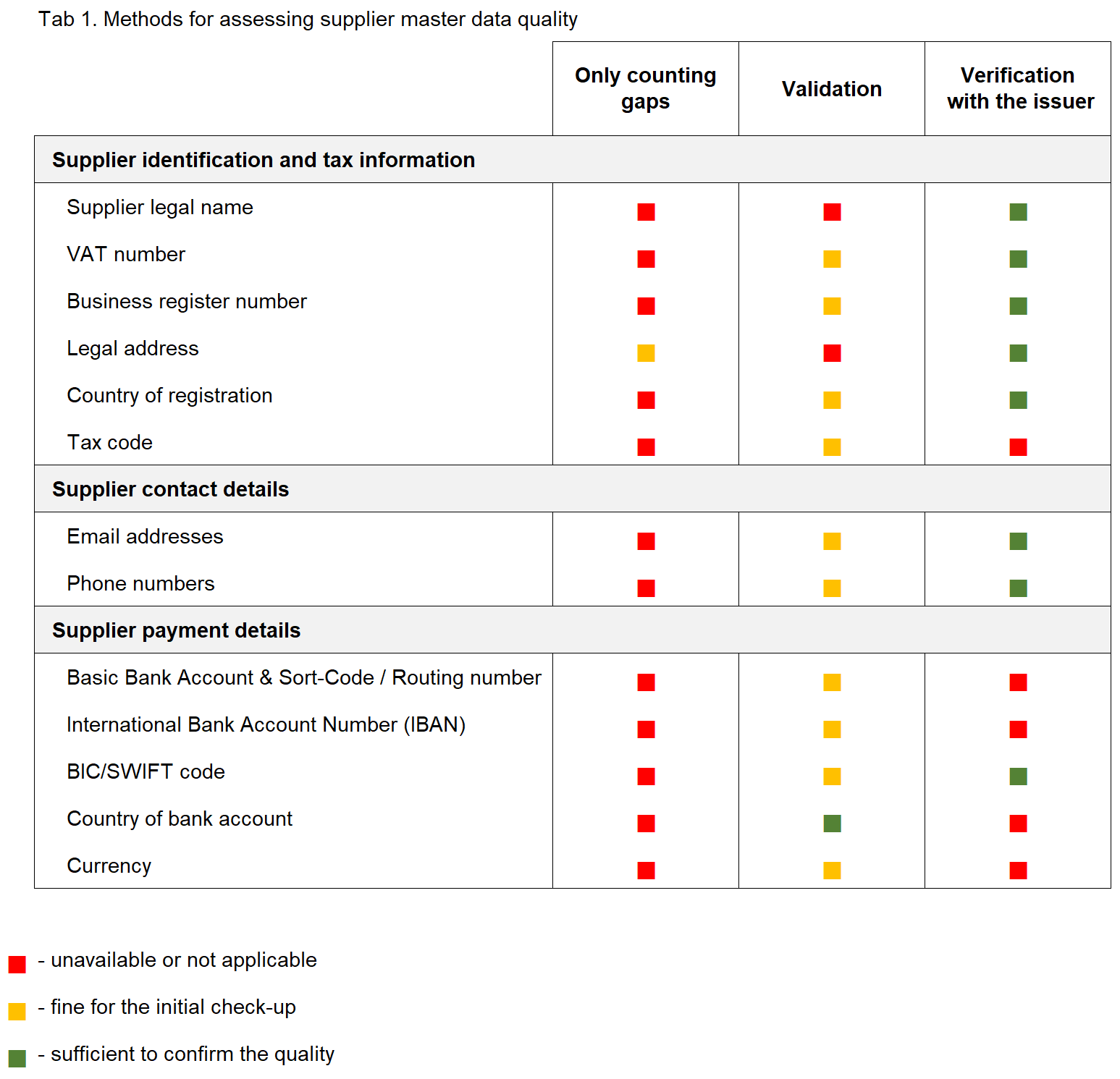
Nevertheless, investments in data verification are paid off totally with comprehensive data cleansing planning because verified data enables the first four essential phases (Diagram 1).

Identify unique legal entities and consolidate records
This step aims to consolidate records related to a specific supplier, allowing:
- specification of the supplier with all related records instead of assigning record per record for a cleansing, thereby avoiding repeated work by different team members, and also supplier confusion due to multiple requests;
- exchanging of some information between records;
- taking action (such as supplier deactivation) and preventing any leftovers in the vendor file;
- identification of duplicates and investigation of their purpose;
- accurately estimating efforts required for data cleansing.
During identification, the official business register number (such as company registration number in the UK, code SIREN in France, KvK-Nummer in the Netherlands) or the DUNS number should be assigned to every line in the vendor file. At this stage, the number may be added to the vendor report, but not necessarily entered into the original system (this can be undertaken during the actual data cleansing).
Algorithms can solve an average of approximately 75 per cent of lines in a vendor file (the result achieved by Datanovel) using all types of information available in that file, and matching it with publicly available official databases. The remaining 25 per cent requires manual investigation and business register number cleansing. Datanovel can also perform this work or equip and coach your staff for solving it effectively.
The set of records is where company registration number/business registration number / DUNS match defines the ‘supplier’. Hereby, when we refer to actions over the ‘supplier’, we mean actions undertaken to all the records related to that supplier.
Legal entity identification can be extended across multiple systems when data consolidation and merging P2P operations in one system are part of the digital transformation programme. In this case, this article’s main principles remain unchanged and should be applied equally to every legacy system; therefore, the supplier definition might include records located in multiple systems.
Identify legal entities for deactivation
Supplier master data cleansing is an excellent reason for posing a question to the Procurement about suppliers who are no longer needed; these could be:
- used only once, but still active on the vendor file;
- not used for a considerable time (therefore, using them again will probably require a full evaluation, equal to onboarding as new);
- eventually replaceable by one of the incumbent suppliers.
According to the Advanced Market Research study (2018), a typical company spends between $585 to $1,000 per supplier annually.
Suppliers assigned for deactivation specified as a list of records in system(s) and provided to the migration team will be excluded from migration. They can be excluded from cleansing, thereby allowing resource savings and releasing more time for cleansing other suppliers. Because such records will not be migrated, do not forget to close all open items linked to them before switching off the legacy system(s).
Identify unnecessary duplicates
Learning about duplicates in the vendor file novels about the past provides tips on establishing structure and governance of master data in the new system. Furthermore, such an analysis is an excellent starting point for understanding how the new system needs to be tailored in order to enable organisational specifics in P2P.
Good duplicates could be created for the following reasons:
- to allow sourcing from a specific site of the supplier;
- to facilitate payments under different payment terms or currency or bank details;
- to enable specific tax conditions such as sourcing of material, services or labour;
- to enable specific approval procedures;
- to enable sourcing from multiple systems.
Three signs can help in ascertaining whether the duplicate is ‘good’:
- a duplicate is somehow linked to a parent account;
- a duplicate is synchronised with a parent account – matching data can be sufficient to confirm that;
- a duplicate contains unique information, but this requires a check on actuality.
Reasons for unnecessary duplicates appearing in the vendor file:
- created after failure to find an existing record (one of the most common reasons for duplicates, and the most common reason for not finding existing records is outdated names);
- created due to lack of data governance and control (because more than one function can create suppliers in the system);
- they might be good duplicates that are no longer required.
Most of the unnecessary duplicates will neither be linked to a parent account nor synchronised, and may also create supply risks and corrode the spend consolidation.
When time permits, any open items linked to unnecessary duplicates should be closed or moved. Moreover, records identified for deactivation ought to be excluded from cleansing and migration. If there is insufficient time to complete all transactions, unnecessary duplicates should be linked to parents, cleansed and migrated in order to enable secure closure in the new system.
Segment and prioritise suppliers
All suppliers can be categorised into four groups (from higher to lower priority for cleansing):
Group A are suppliers with banking details issues as they should be the top priority for your data cleansing team. Regardless of which method of verification you are implementing, any process will require engagement and meaningful response from the suppliers; some of whom do not rush to provide it, thereby requiring multiple chases.
The response time often depends on supplier complexity and how such suppliers value you as a customer. This organisational complexity may result in your request to reach the right person being time-consuming. Their attitude usually depends on the percentage of turnover that they make on your business. When this percentage is relatively low (below 1 per cent), you can expect delays and reluctance in the responses to your requests, typically attributed to large organisations at the tail end of your supply chain. Procurement can provide valuable advice on such risks; alternatively:
- Obtain spend data for each record and consolidate as per supplier;
- Use the company registration / business register or DUNS number to obtain turnover for the past financial year from services such as D&B or Endole. Datanovel may assist in receiving turnover data for all suppliers in bulk.
- Estimate the percentage of your business in each supplier turnover.
Sort suppliers according to the impact you make on their turnover: least impact = longer anticipated response time. Suppliers with a longer response time should be given a higher priority, in order to make more calendar time for multiple chases that will probably be needed.
Group B are suppliers with missing or outdated contact details, but excluding those in Group A. It is quicker to obtain the up-to-date phone number and email address during the first call (sometimes reception can help) than your account manager. Therefore, this group has the least concern for chasing and obtaining a response, although the group is usually significant in volume.
Group C includes all suppliers with no banking or payment details’ issues but still requires to be contacted in order to clarify some of the master data – in most cases for the valid VAT number or the tax code (such as UK UTR).
The lastby priority, Group D, includes suppliers with master data that is already fully available (no need to contact the supplier) but it is necessary to confirm to the requirements (see the following chapter), for example:
- update legal name or legal address based on information from the official register;
- add business register number;
- link up duplications and save the reason why a duplicate exists;
- semantic corrections of email addresses and phone numbers (such as removing spaces, commas and other unnecessary characters, as required by automated sending from the new system);
- add any additional business data necessary to facilitate an updated P2P process in the new system;
- add past year turnover, thereby making it available in the system if required.
Suppliers from groups A, B and C also need this type of cleansing.
Spend data can be used to set priorities in groups B, C and D. The more you buy from the supplier, the more critical their master data is.
Estimate efforts, develop tactics and plan actions
Build a data map for the target supplier profile and create an instruction
The system’s standard supplier profile is not a data map (unfortunately, it is a common mistake to assume that it is). The typical supplier profile in the ERP/S2C/P2P system provides hundreds of fields in which to store any type of supplier information with the primary purpose of enabling flexibility for fitting in any kind of processes in any sector. In practice, only a small number of fields is typically needed to run a specific business successfully. The designer of the target data model ought to understand both the company and the existing practices, and how these will improve after the transformation.
The target data map must explicitly indicate what field is for which data element and what fields are not used. Some fields should be used for the supplier’s information, whereas others should be used internally during supplier onboarding and evaluation processes. These include risk level evaluation, approval process, pay priority, and tax classification and others. Moreover, such business information should be specified, although this cleansing is usually performed with input from various business functions, designed logic, and with standard ETL tools. It is unnecessary to contact the supplier and enter business data manually into the system; therefore, cleansing of business information is beyond the scope of this article.
The target data map must be compatible with both the legacy system’s supplier profile and the supplier profile target system. Where field naming differs, the connection between the two must be specified.
Finally, the data map should consider local-specifics; for example, that the Swiss UID number (Business Identification Number) matches the VAT number for Swiss companies. IBAN is not mandatory or available in some countries; therefore alternative formats of banking details ought to be considered and other fields in the system must be used.
In addition to the data map, the attached instructions should include:
Instructions for validation or verification of the information entered manually into the free entry (text) fields.
Directions on how to create and store links between records in the legacy system:
- Links between the primary record (parent) and necessary duplicates (child), including the type of relationship (the reason for duplication), such as: to allow sourcing from a specific site of the supplier; to facilitate payments under different payment terms, currency, bank details; to enable specific tax conditions; to enable specific approval procedures.
- Links between the primary record and unnecessary duplicates if they have to be carried over to the new system due to open items.
- Links between legal entities from the same family group (same owner or a significant influencer).
- Links to the same legal entities in other legacy systems.
The list of fields that should be synchronised between parent and child and fields that should not be synchronised, according to the relationship type.
Although the link issue might be rather complex, it is worth investing time and effort in a thoughtful approach because this will deliver valuable benefits:
- Supplier hierarchy can be quickly and accurately restored in the new system;
- Enable automatic synchronisation (possibly cross system) of complicated multi-record suppliers removing manual work and increasing the data accuracy by eliminating possible human errors;
- Improve supplier and category consolidation, and spend reporting.
Most systems allow a designed way of storing some types of links between records (for example, links to an invoice account). Unfortunately, almost none have sufficient functionality for storing all kinds of relationships. The practical approach for retaining the link is to save a reliable supplier identification (such as company registration number) in one of the non-used free-text fields, with the same for the relationship type.
The produced document becomes a bible for the data cleansing team, and a great insight into how to amend instructions for the BAU vendor management team. The technical data migration team will also ask for this document because it is critically necessary for migrating suppliers successfully.
Plan actions and calculate required FTEs
Below is an example of how FTE resource can be calculated (Table 3) based on measured data quality, segmentation and required activities (Table 2.).

Develop the tactics
In the example in Table 3, 7.3 FTEs are needed for cleansing a vendor file. If the estimation is inaccurate, tactics will help to:
- ensure crucial data is ready for the deadline;
- provide more calendar time for cleansing high-difficulty suppliers or suppliers from specific countries;
- flag insufficient resources at an early stage in order to engage more FTEs or decide which data can be cleansed after the deadline;
- exploit potential in optimisation and efficiency.
Both time estimations and tactics are the primary inputs for establishing a project schedule.
An example of tactics:
Week 1:
- Allocate 2 FTEs to work on Group B to find generic contact details and immediately issue RFI requesting up-to-date contact details for placing orders and forwarding remittance advice. The usual response rate of similar RFI’s is approximately 15 per cent; therefore, about 32 hours can be saved as per example in Table 2.
- Allocate the remaining FTEs to call and chase randomly picked suppliers in Group A. Measure the progress and collect feedback from the team for evaluating whether you have sufficient power to coerce suppliers to comply with the required actions and whatever resources are realistically needed in order to meet the deadline.
Week 2:
- Leverage the resource between groups A and B, ensuring all bank details’ issues are resolved by the end of Week 4 (the deadline as per example).
- Team members allocated to Group B should begin to chase suppliers who did not respond to RFI, requesting for up-to-date contact details over the phone.
Week 3:
- Continue working on groups A and B.
- Begin allocating resources to groups C and D if the first two groups’ progress allows.
Prepare the team, tools and temporary process fix
Assemble the team
The main requirements are attention to detail, ability to undertake routine work and procedural discipline. The excellent planning and organisation of data cleansing (hopefully, this article helps) can prevent emergencies and help team members to focus on specific tasks; therefore, it is worth seeking skills in three essential areas:
- identifying and verifying legal entities with knowledge of specifics in each of the markets you are sourcing.
- verifying of banking details with knowledge of best practices in specific markets;
- verifying and collecting contact details.
You might need to introduce people with specific skills, either by finding them internally or by employing temporary workers (people who specialise in data cleansing are available in the market). As soon as you employ such people, provide them with training on the target supplier profile requirement, expected data quality level and tools in order to achieve this. If the team is large, select a champion and individually train that person to pass knowledge to others while preparing a kick-off.
Prepare the tools
The most appropriate toolkit for your team is the key to productivity and data quality. Datanovel specialises in developing simple and straightforward instruments for data cleansing:
- No installation required (IT involvement is not needed);
- No training or manuals required because all tools are Excel-based;
- Integration with official databases for instant extraction of necessary data and confirmation;
- No data leaves your PC.
These include:
- Supplier RFI form template. Datanovel includes data validation functionality to prevent extra communication for data clarification.
- Supplier RFI forms consolidation tool. Datanovel includes verification with official databases into this tool for ensuring data quality (such as verification of the legal name and address, VAT number, phone number carrier lookup, email address bounce check), plus the automatic generation of instructions for duplicates synchronisation where required.
- Data cleansing workflow tool. Datanovel includes best practices of the assignment and team management to the workflow; furthermore, segregation of duties are included where required.
Other solutions and tricks for increasing the productivity of the team:
- Set up a group mailbox for sending out RFIs, allowing anyone in your team to check for supplier response or to chase by using previously investigated generic contacts.
- Use bulk SMS for chasing (service providers such as TextMagic or TextAnywhere).
- Create a shared spreadsheet to store and share metadata (such as lists of all supplier duplicates across legacy systems, investigated business register numbers, DUNS numbers, priorities), registering and tracking assignments.
- Give each supplier a project number that indicates the priority (for example, suppliers in Group A start from 10000, Group B start from 20000 and so on.
- Connect the team with the vendor invoice register in order to use information from invoices for confirming the legitimacy of requests.
When the team is allowed to use any third-party web services (instead of Datanovel Excel-based tools) for a manual data validation or verification (such as IBANCalculator or BankCodes). Never allow the exclusive use of a single service, but prepare multiple options for random selection so that none of these services has full exposure on your supply chain.
Introduce temporary process fixes
The existing supplier management process creates data issues that are targeted by the prepared data cleansing activities. Digital transformation will possibly bring tighter data governance, preventing the appearance of data issues, but it will only come into effect with go-live. However, on approaching the deadline with almost 100 per cent vendor data quality requires a temperate patch to the legacy processes for stopping ‘the leaking tap’.
Introducing in such temperate fixes requires an analysis of the existing process in order to understand precisely how incorrect data enters the system or is being corrupted or duplicated during some BAU process. It is not uncommon for the supplier evaluation and onboarding process to emerge and evolve with the organisation; therefore, processes are not always adequately formalised for the analysis. Datanovel can help to discover, map, and analyse the existing process, evaluate steps that should be temporarily fixed, and provide tools for minimising the impact to cycle time.
Process fix implementation for a legacy process is a change management challenge which should be avoided when data can be fixed at the ETL process level during data migration. Usually, a process fix is the only solution when the data becomes irreversibly changed, removed or added without a compliant review or verification.
An example
Suppose that the new payment system was introduced to the Accounts Payable department some time ago. IBAN is required to pay suppliers in this new system. However, the current supplier management process collects, verifies and stores only the basic account number and sort code. Therefore, the AP misses IBAN on the vendor master file. Suppose the AP has been given an explicit instruction not to take any payment details from invoices (which makes sense from the security perspective). The AP has already submitted its request to amend the supplier management process; however, this request was postponed due to the upcoming transformation. Because payments cannot be delayed, as a preliminary solution, the AP has decided to use an unofficial tool for generating IBANs using the account number, sort code and supplier country, and then add created IBAN to the vendor master.
Although the solution from the AP is understandable, it poses several risks to the organisation:
- None of the available IBAN generation tools can guarantee 100 per cent accuracy in IBAN prediction. Therefore, some payments might be lost or rejected.
- If the payment is lost, the supplier has legal grounds to dispute the transaction because it was not made to authorised requisites (generated IBAN).
- Through the volume of incoming requests from the same IP, the owners of an unofficial tool might realise what organisation and for which purpose it uses the tool. A possible risk is that owners might decide to take advantage of this information.
- The process of generating IBAN might be non-compliant (for example, the requirement to segregate duties for entering and independently checking the entry is not satisfied), thereby creating risks of internal fraud.
The possible solution:
- For the data cleansing team, prioritise verification of all IBANs previously entered by the AP, and not yet confirmed by the payee after the successful transaction.
- Loop the data cleansing team into the AP process of IBAN generation as per Diagram 2.
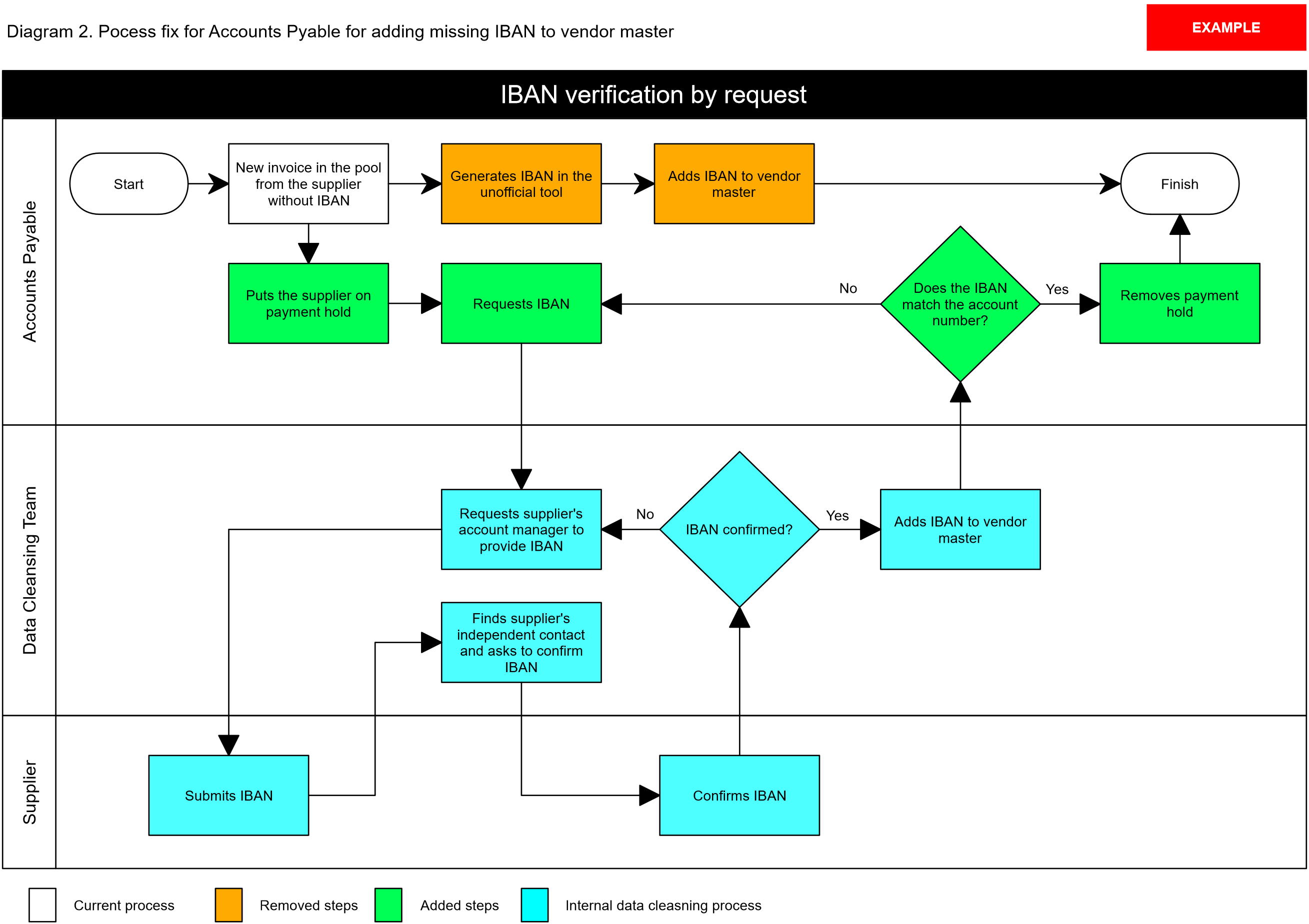
Kick-off
When the team is trained and equipped and the existing process is fixed, the kick-off meeting can be held. Describe the action plan and each person’s responsibility within it. Encourage people to discuss the most difficult suppliers, communication issues, tactics and any other project matters that could spark a conversation. This will clarify roles and responsibilities, trigger experience exchange and possibly highlight some previously overseen problems. Discuss how the team can overcome difficulties together.
Ideally, suppose that one of the senior stakeholders can attend the meeting. Because data cleansing is often conceived to be insignificant, it is essential to show that senior management does not share this view. The team should become inspired by the challenge and its criticality within the transformation project.
According to the Deloitte Global Chief Procurement Officer Survey (2019), 57% of surveyed CPOs top the quality of data as the main barrier to technology adaptation
Furthermore, describe the target which is the excellence in data quality and how it will be measured and monitored daily and weekly. Mention how stakeholders will be updated and what kind of support may be received from their teams.
Need help in planning data cleansing? Please enquire us today for: